Para estar al día de sus eventos pasate por la web y registrate sin falta en su meetup. La Comunidad de Cloud esta creciendo y en una zona con mas proyección es en todo America, especialmente en Latino America.
En esta entrada de Google Cloud Español os hablare que software de diagrama podríamos usar para representar los objetos de plataforma Google Cloud y proporcionar soluciones donde mostrar los diagramas de arquitectura GCP. Ademas Puede crear fácilmente cualquier diagrama de la plataforma Google Cloud utilizando sus iconos GCP prefabricados, Pero para empezar.....
También hay 50 diagramas de muestra que puedes abrir en las Presentaciones de Google, en PowerPoint y en Lucidchart. Estos iconos y diagramas están pensados para hacer referencia a las herramientas y a la tecnología de Google de forma precisa en arquitecturas, entradas de blog, informes, hojas de datos, carteles y otros materiales técnicos.
Software para Diagramas de Google Cloud Platform
Hay distintos incluso pero yo uso u recomiendo el software draw.io que ofrece funciones y funciones de proyectos de Google Cloud Platform con varios íconos, símbolos y la conveniente interfaz de usuario de arrastrar y soltar. Puede crear rápidamente cualquier diagrama de GCP arrastrando y soltando iconos de GCP, organizándolos y conectándolos, y anotándolos con texto. Una vez hecho, también puede guardar su trabajo en la nube o exportarlo en diferentes formatos, incluidos documentos PDF y de Office.
Ademas Google nos proporciona un conjunto de iconos oficiales de Google para esta herramienta y funciona en un entorno web de cualquier plataforma, una aplicación web que nos permite crear diagramas de todo tipo desde nuestro navegador, de manera cómoda y sin tener que adquirir licencias de Microsoft Visio o similares.Draw.io tiene además la ventaja de incluir ya imágenes de Amazon, Microsoft Azure, Veeam, y muchos otros, y además viene con ejemplos.
Nota del editor: En Google Cloud español os presentamos la sexta entrega de una serie de videos y blogs en siete partes de Google Developer Advocate Sandeep Dinesh sobre cómo aprovechar al máximo su entorno de Kubernetes.
La mayoría de los usuarios de Kubernetes, es probable que use servicios que no pertenecen a su clúster. Por ejemplo, tal vez use la API Twillio para enviar mensajes de texto, o tal vez la API Google Cloud Vision para hacer análisis de imágenes.
Si en sus aplicaciones de diferentes entornos se conectan al mismo punto externo y no tienen pensado llevar el servicio externo a su clúster de Kubernetes, es correcto utilizar el punto extremo de servicio externalizado directamente en su código. Sin embargo, hay muchos escenarios donde este no es el caso.
Un buen ejemplo de esto son las bases de datos. Si bien algunas bases de datos nativas de la nube de Google, como Cloud Firestore o Cloud Spanner, usan un punto final único para todos los accesos, la mayoría de las bases de datos tienen puntos finales separados para diferentes instancias.
En este punto, puede estar pensando que una buena solución para encontrar el punto final es usar ConfigMaps. Simplemente almacene la dirección del punto final en una ConfigMap, y úsela en su código como una variable de entorno.
Si bien esta solución funciona, hay algunas desventajas. Debe modificar su implementación para incluir ConfigMap y escribir código adicional para leer desde las variables de entorno. Pero lo más importante es que, si la dirección del punto final cambia, es posible que deba reiniciar todos los contenedores en ejecución para obtener la dirección del punto final actualizada.
En este episodio de "Kubernetes Best Practices", aprenderemos a aprovechar los mecanismos integrados de descubrimiento de servicios de Kubernetes para servicios que se ejecutan fuera del clúster, ¡como lo haría con los servicios dentro del clúster! Esto le brinda igualdad en sus entornos de desarrollo y producción, y si finalmente mueve el servicio dentro del clúster, no tiene que cambiar el código en absoluto.
Escenario 1: base de datos fuera del clúster con dirección IP
Un escenario muy común es cuando aloja su propia base de datos, pero lo hace fuera del clúster, por ejemplo, en una instancia de Google Compute Engine. Esto es muy común si ejecuta algunos servicios dentro de Kubernetes y algunos fuera, o necesita más personalización o control de lo que permite Kubernetes.
Con suerte, en algún momento, puede mover todos los servicios dentro del clúster, pero hasta entonces está viviendo en un mundo híbrido. Afortunadamente, puede usar servicios de Kubernetes estáticos para controlar el entorno de conexión.
En este ejemplo, creé un servidor MongoDB usando Cloud Launcher. Debido a que se creó en la misma red (o VPC) que el clúster Kubernetes, se puede acceder utilizando la dirección IP interna, está presenta un alto rendimiento. En Google Cloud, esta es la configuración predeterminada, por lo que no es necesario nada especial para configurar.
Ahora que tenemos la dirección IP, el primer paso es crear un servicio:
Es posible que observe que no hay selectores de Pod para este servicio. Esto crea un servicio, pero no sabe a dónde enviar el tráfico. Esto le permite crear manualmente un objeto Endpoints que recibirá tráfico de este servicio.
Puede ver que los puntos finales definen manualmente la dirección IP de la base de datos y usa el mismo nombre que el servicio. Kubernetes usa todas las direcciones IP definidas en los puntos finales como si fueran pods de Kubernetes regulares. Ahora puede acceder a la base de datos con una cadena de conexión simple:
mongodb://mongo
NOTA: ¡No necesita usar direcciones IP en su código! Si la dirección IP cambia en el futuro, puede actualizar el Endpoint con la nueva dirección IP, y sus aplicaciones no necesitarán realizar cambios.
Escenario 2: base de datos remotamente alojada con URI
Si está utilizando un servicio de base de datos alojado de un tercero, es probable que le proporcionen un identificador de recursos unificado (URI) que puede usar para conectarse. Si le dan una dirección IP, puede usar el método que está en el Escenario 1.
En este ejemplo, tengo dos bases de datos MongoDB alojadas en mLab. Uno de ellos es mi base de datos de desarrollo, y el otro es producción.
Las cadenas de conexión para estas bases de datos son las siguientes:
mLab le proporciona un URI dinámico y un puerto dinámico, y puede ver que ambos son diferentes. Usemos Kubernetes para crear una capa de abstracción sobre estas diferencias. En este ejemplo, vamos a conectarnos a la base de datos de desarrollo.
Puede crear un servicio Kubernetes "ExternalName", que le proporciona un servicio Kubernetes estático que redirecciona el tráfico al servicio externo. Este servicio realiza una redirección de CNAME simple a nivel de kernel, por lo que su rendimiento tiene un impacto mínimo.
Ahora, puede utilizar una cadena de conexión mucho más simplificada:
mongodb://<dbuser>:<dbpassword>@mongo:<port>/dev
Porque "ExternalName" utiliza Redirección CNAME, no puede hacer reasignación de puertos. Esto podría estar bien para los servicios con puertos estáticos, pero desafortunadamente no es suficiente en este ejemplo, donde el puerto es dinámico. El nivel libre de mLab te da un número de puerto dinámico y no puedes cambiarlo. Esto significa que necesita una cadena de conexión diferente para dev y prod.
Sin embargo, si puede obtener la dirección IP, entonces puede hacer la reasignación de puertos, como explicaré en la siguiente sección. Escenario
3: Base de datos alojada remotamente con URI y reasignación de puertos.
El redireccionamiento CNAME funciona muy bien para los servicios con el mismo puerto para cada entorno, no se cumple en los escenarios donde los diferentes puntos finales para cada entorno usan diferentes puertos. Afortunadamente, podemos solucionarlo utilizando algunas herramientas básicas.
El primer paso es obtener la dirección IP del URI.
Si ejecuta el comando dig, nslookup, hostname o ping contra el URI, puede obtener la dirección IP de la base de datos.
Ahora puede crear un servicio que reasigne el puerto mLab y un punto final para esta dirección IP.
Nota: ¡Un URI podría usar DNS para balancear la carga a varias direcciones IP, por lo que este método puede ser peligroso si cambian las direcciones IP!.
Si obtiene varias direcciones IP del comando anterior, puede incluirlas en el YAML de puntos finales, y Kubernetes equilibrará el tráfico de carga con todas las direcciones IP.
Con esto, puede conectarse a la base de datos remota sin necesidad de especificar el puerto. . ¡El servicio de Kubernetes hace la reasignación de puertos de forma transparente!
mongodb://<dbuser>:<dbpassword>@mongo/dev
Conclusion
Mapear servicios externos a los internos le brinda la flexibilidad de incorporar estos servicios en el clúster en el futuro mientras minimiza los esfuerzos de refactorización. Incluso si no planea traerlos hoy, nunca se sabe lo que puede traer el mañana. Además, facilita la administración y comprensión de los servicios externos que usa su organización.
Si el servicio externo tiene un nombre de dominio válido y no necesita la reasignación de puertos, el uso del tipo de servicio "ExternalName" es una manera fácil y rápida. mapear el servicio externo a uno interno. Si no tiene un nombre de dominio o necesita hacer una reasignación de puertos, simplemente agregue las direcciones IP a un punto final y utilícelo en su lugar.
En Google Cloud Español hablamos de seguridad y aislamiento de los Contenedores de Software Engineer han revolucionado la forma en que desarrollamos, empaquetamos y desplegamos aplicaciones. Sin embargo, la zona de código del sistema expuesta a los contenedores es lo suficientemente amplia como para que muchos expertos en seguridad no los recomienden para ejecutar aplicaciones no confiables o potencialmente maliciosas.
El creciente deseo de ejecutar cargas de trabajo más heterogéneas y menos confiables ha creado un nuevo interés en los contenedores usando espacios aislado: contenedores que ayudan a proporcionar un límite de aislamiento seguro entre el sistema operativo host y la aplicación que se ejecuta dentro del contenedor.
Con ese fin, nos gustaría presentar gVisor, un nuevo tipo de entorno limitado que ayuda a proporcionar un aislamiento seguro para los contenedores, a la vez que es más liviano que una máquina virtual (VM). gVisor se integra con Docker y Kubernetes, por lo que es simple y fácil ejecutar contenedores de espacio aislado en entornos de producción.
Los contenedores tradicionales de Linux no son cajas cerradas
Las aplicaciones que se ejecutan en contenedores Linux tradicionales acceden a los recursos del sistema de la misma forma que lo hacen las aplicaciones regulares (no en contenedor): realizando llamadas al sistema directamente al núcleo del host. El kernel se ejecuta en un modo privilegiado que le permite interactuar con el hardware necesario y devolver los resultados a la aplicación.
Con los contenedores tradicionales, el kernel impone algunos límites a los recursos a los que puede acceder la aplicación. Estos límites se implementan mediante el uso de cgroups y espacios de nombres de Linux, pero no todos los recursos se pueden controlar a través de estos mecanismos.
Además, incluso con estos límites, el núcleo aún expone una gran área de superficie que las aplicaciones maliciosas pueden atacar directamente. Las características Kernel como los filtros seccomp pueden proporcionar un mejor aislamiento entre la aplicación y el núcleo del host, pero requieren que el usuario cree una lista blanca predefinida de llamadas al sistema.
En la práctica, a menudo es difícil saber qué llamadas al sistema requerirá una aplicación de antemano. Los filtros también brindan poca ayuda cuando se descubre una vulnerabilidad en una llamada al sistema que requiere su aplicación.
Tecnología de contenedor basada en VM existente
Un enfoque para mejorar el aislamiento de contenedores es ejecutar cada contenedor en su propia máquina virtual (VM). Esto le da a cada contenedor su propia "máquina", incluidos kernel y dispositivos virtualizados, completamente separados del host. Incluso si hay una vulnerabilidad en el invitado, el hipervisor todavía aísla el host, así como otras aplicaciones / contenedores que se ejecutan en el host.
La ejecución de contenedores en distintas máquinas virtuales proporciona un gran aislamiento, compatibilidad y rendimiento, pero también puede requerir una mayor huella de recursos. Los contenedores Kata son un proyecto de código abierto que utiliza VM desmanteladas para mantener el espacio de recursos mínimo y maximizar el rendimiento para el aislamiento de contenedores. Al igual que gVisor, Kata contiene un tiempo de ejecución de Open Container Initiative (OCI) que es compatible con Docker y Kubernetes.
Contenedores de espacio aislado con gVisor
gVisor es más liviano que una VM mientras mantiene un nivel similar de aislamiento. El núcleo de gVisor es un núcleo que se ejecuta como un proceso normal y sin privilegios que admite la mayoría de las llamadas al sistema Linux. Este núcleo está escrito en Go, que fue elegido por su seguridad de tipo memoria y tipo. Al igual que en una máquina virtual, una aplicación que se ejecuta en una caja y gVisor obtiene su propio kernel y un conjunto de dispositivos virtualizados, distintos del host y de otras cajas.
gVisor proporciona un fuerte límite de aislamiento al interceptar las llamadas al sistema de aplicaciones y actuar como el núcleo invitado, todo mientras se ejecuta en el espacio de usuario. A diferencia de una VM que requiere un conjunto fijo de recursos en la creación, gVisor puede acomodar los recursos cambiantes a lo largo del tiempo, como lo hacen la mayoría de los procesos normales de Linux. gVisor se puede considerar como un sistema operativo extremadamente paravirtualizado con una huella de recursos flexible y un costo fijo menor que una VM completa. Sin embargo, esta flexibilidad tiene el precio de una mayor sobrecarga de llamadas por sistema y compatibilidad de aplicaciones, sobre esto más sobre eso a continuación.
"Las cargas de trabajo seguras son una prioridad para la industria. Nos alienta ver enfoques innovadores como gVisor y esperamos colaborar en la aclaración de especificaciones y en la mejora de los componentes técnicos conjuntos para brindar seguridad adicional al ecosistema". - Samuel Ortiz, miembro del Comité Directivo Técnico de Kata e Ingeniero Principal en Intel Corporation
"Se alienta a Hyper a ver el nuevo enfoque de gVisor para el aislamiento de contenedores. La industria requiere un ecosistema robusto de tecnologías de contenedores seguros, y esperamos colaborar en gVisor para ayudar a traer contenedores seguros a la corriente principal ". - Xu Wang, miembro del Comité Directivo Técnico de Kata y CTO en Hyper.sh
Integrado con Docker y Kubernetes
El tiempo de ejecución de gVisor se integra sin problemas con Docker y Kubernetes a través de runsc (abreviatura de "ejecutar contenedor de espacio aislado"), que se ajusta a la API de tiempo de ejecución de OCI. El tiempo de ejecución de runsc es intercambiable con runc, el tiempo de ejecución de contenedor predeterminado de Docker. La instalación es simple; una vez instalado, solo se necesita una bandera adicional para ejecutar un contenedor de espacio aislado en Docker:
$ docker run --runtime=runsc hello-world
$ docker run --runtime=runsc -p 3306:3306 mysql
En Kubernetes, la mayor parte del aislamiento de los recursos se produce en el nivel del pod, lo que hace que el pod sea un ajuste natural para un límite de la zona de pruebas gVisor. La comunidad de Kubernetes está formalizando actualmente la API de la sandbox pod, pero el soporte experimental está disponible hoy.
El tiempo de ejecución de runsc puede ejecutar pods de espacio aislado en un clúster de Kubernetes mediante el uso de los proyectos cri-o cri-containerd, que convierten los mensajes de Kubelet en comandos de tiempo de ejecución OCI. gVisor implementa una gran parte de la API del sistema Linux (200 llamadas al sistema y conteo), pero no todas. Algunas llamadas al sistema y argumentos no son actualmente compatibles, como lo son algunas partes de los sistemas de archivos / proc y / sys. Como resultado, no todas las aplicaciones se ejecutarán dentro de gVisor, pero muchas funcionarán perfectamente, incluidas Node.js, Java 8, MySQL, Jenkins, Apache, Redis, MongoDB y muchas más.
Empezando
Como desarrolladores, queremos lo mejor de ambos mundos: la facilidad de uso y la portabilidad de los contenedores, y el aislamiento de los recursos de las máquinas virtuales. Creemos que gVisor es un gran paso en esa dirección. Consulte nuestro informe en GitHub para saber cómo comenzar con gVisor y obtener más información sobre los detalles técnicos. ¡Y asegúrese de unirse a nuestro grupo de Google para participar en la discusión!
Nota del editor: En Google Cloud Español seguimos con las entregas de serie de videos y blogs en siete partes de Google Developer Advocate Sandeep Dinesh sobre cómo aprovechar al máximo su entorno de Kubernetes.
Cuando se trata de sistemas distribuidos, manejar los fallo sen muy importante. Kubernetes ayuda con esto al utilizar controladores que pueden ver el estado de su sistema y reiniciar los servicios que han dejado de funcionar. Por otro lado, Kubernetes a menudo puede terminar su aplicación a la fuerza como parte del funcionamiento normal del sistema.
En este episodio de "Kubernes best Practices", veamos cómo puede ayudar a Kubernetes a hacer su trabajo de manera más eficiente y reducir el tiempo de inactividad que puede aparecer en sus aplicaciones.
Antes de la aparción de los contenedores, la mayoría de las aplicaciones se ejecutaban en máquinas virtuales o máquinas físicas. Si una aplicación se bloquea, llevó bastante tiempo arrancar o reinicar de nuevo. Si solo tenía una o dos máquinas para ejecutar la aplicación, este tipo de tiempo de recuperación es inaceptable.
En cambio, se volvió común usar la supervisión a nivel de proceso para reiniciar aplicaciones cuando se bloqueaban. Si la aplicación se bloqueó, el proceso de monitoreo podría capturar el código de salida y reiniciar la aplicación al instante.
Con la llegada de sistemas como Kubernetes, los sistemas de monitoreo de procesos ya no son necesarios, ya que Kubernetes maneja el reinicio de las aplicaciones bloqueadas. Kubernetes usa un ciclo de eventos para asegurarse de que los recursos como los contenedores y los nodos están en un estado correcto o funcionado. Esto significa que ya no necesita ejecutar estos procesos de monitoreo manualmente. Si un recurso no pasa un control de checking, Kubernetes automáticamente activa un proceso de reinicio.
Tienes ya publicado en el blog que indican como activar el checking de tus servicios para ver cómo puede configurar comprobaciones de salud personalizadas.
El ciclo de vida de terminación de Kubernetes
Kubernetes hace mucho más que controlar su aplicación en caso de fallo. Puede crear más copias de su aplicación para ejecutar en múltiples máquinas, actualizar su aplicación e incluso ejecutar múltiples versiones de su aplicación al mismo tiempo.
Esto significa que hay muchas razones por las que Kubernetes podría terminar un contenedor que este perfecto. Si actualiza su implementación con una actualización continua, Kubernetes termina lentamente las antiguas unidades mientras activa otras nuevas. Si termina un nodo, Kubernetes termina todas los pods en ese nodo. Si un nodo se queda sin recursos, Kubernetes termina los pods para liberar esos recursos (consulte esta entrada anterior para obtener más información sobre los recursos).
¡Es importante que su aplicación controle la terminación con cuidado para que tenga un impacto mínimo en el usuario final y el tiempo de recuperación sea lo más rápido posible!
En la práctica, esto significa que su aplicación necesita controlar el mensaje SIGTERM y comenzar a apagar cuando lo recibe. Esto significa guardar todos los datos que se deben guardar, cerrar las conexiones de red, finalizar el trabajo restante y otras tareas similares.
Una vez que Kubernetes ha decidido finalizar su pod, se produce una serie de eventos. Veamos cada paso del ciclo de vida de terminación de Kubernetes.
1 - Pod se establece en el estado "Terminating" y se elimina de la lista de puntos finales de todos los Servicios
En este punto, el pod deja de recibir nuevo tráfico. Los contenedores que se ejecutan en los pods no se verán afectados.
2 - Se ejecuta preStop Hook
PreStop Hook es un comando especial o una solicitud http que se envía a los contenedores en el pod.
Si su aplicación no se cierra de forma correcto (el clasico "cuelge de la aplicación"), al recibir un SIGTERM, puede usar este hook para activar un apagado correcto. La mayoría de los programas se cierran correctamente al recibir un SIGTERM, pero si utiliza un código de terceros o está administrando un sistema que no tiene control, el Hook preStop es una gran manera de activar un apagado ordenado sin modificar la aplicación.
3 - La señal SIGTERM se envía al pod
En este punto, Kubernetes enviará una señal SIGTERM a los contenedores en el pod. Esta señal les permite a los contenedores saber que van a cerrar pronto.
Tu código debería escuchar este evento y comenzar a cerrarse limpiamente en este punto. Esto puede incluir detener cualquier conexión de larga duración (como una conexión a una base de datos o un flujo de WebSocket), guardar el estado actual, o algo por el estilo.
Incluso si está utilizando el Hook preStop, es importante que pruebe lo que le sucede a su aplicación si le envía una señal SIGTERM, ¡para que no se sorprenda de la producción!
4 - Kubernetes espera un período de gracia
En este punto, Kubernetes espera durante un tiempo específico llamado "período de gracia" -> termination grace, de terminación. Por defecto, esto es 30 segundos. Es importante tener en cuenta que esto sucede en paralelo al Hook preStop y la señal SIGTERM. Kubernetes no espera a que finalice el Hook preStop.
Si su aplicación termina cerrándose y se cierra antes de finalizar terminationGracePeriod, Kubernetes pasa al siguiente paso inmediatamente.
Si su módulo se demora generalmente más de 30 segundos para apagarse, asegúrese de aumentar el período de gracia. Puede hacerlo configurando la opción terminationGracePeriodSeconds en el Pod YAML. Por ejemplo, para cambiarlo a 60 segundos:
5 - La señal de SIGKILL se envía al pod y se retira el pod
Si los contenedores siguen funcionando después del período de gracia, se les envía la señal SIGKILL y se los elimina por la fuerza. En este punto, todos los objetos de Kubernetes se limpian también.
Conclusión
Kubernetes puede finalizar los pods por una variedad de razones, y asegurarse de que su aplicación maneje estas terminaciones correctamente es fundamental para crear un sistema estable y proporcionar una excelente experiencia de usuario.
La creación de redes es una construcción fundamental para cualquier aplicación, sin embargo, también es un concepto muy complejo. Únase a nosotros mientras hablamos de Google Cloud Platform Networking 101 y aprenda a construir entornos de aplicaciones escalables y seguros utilizando la tecnología Cloud Networking. Específicamente, debatiremos cómo Google toma las bases del desarrollo de aplicaciones para el próximo nivel utilizando tanto tecnologías heredadas como nuevas tecnologías y conceptos de Redes.
La idea de este articulo es que se pueda subir un archivo de cualquier tipo (pdf,image,etc) a tu Bucket en el Storage de Goolge usando algunas lineas de Python.
#1) Lo Primero que debemos de hacer es la instalación de la libreria.
$ pip install google-cloud-storage
#2) Las siguientes lineas de código muestran como de fácil se pueden subir archivos al Cloud Storage justo al lado comentare que significa cada una para dejar todo claro.
#Librerias necesarias
$ from google.cloud.storage import Blob
$ from google.cloud import storag
#Se instancia la clase de Cloud Storage para poder comunicarnos directamente con la nube.
$ client = storage.Client(project='PROJECT-ID')
#Seleccionamos el bucket necesario para realizar las operaciones que queramos como subir archivos.
$ bucket = client.get_bucket('NAME-BUCKET')
#Se crea un Objeto de tipo Blob con un nombre que deseamos que vaya a tener dentro del bucket.
$ blob = Blob('NAME.png', bucket)
#Ahora le decimos al blog que suba el archivo en dicha dirección a nuestro bucket pasando dos parametros la PATH del file y el contentex type.
$ blob.upload_from_filename('/PATH/TO/FILE.png','image/png')
#Hacemos que el archivo sea publico si así lo deseamos
$ blob.make_public()
#Se imprime la url del bucket para poder acceder al archivo a través de ella esta luego puede ser compartida o guardada en una BD.
$ print blob.public_url
Así de simple con una cuantas lineas de Python podemos incrustar en nuestra aplicación el uso del Cloud Storage de Google.
Les dejo el enlace de la librería para que puedan explorar las diversas opciones que se pueden hacer en el Storage y puedan adaptarlas a sus necesidades.
Cuando en Kubernetes se programa un Pod, es importante que los contenedores tengan recursos suficientes para que puedan trabajar. Si se programa una aplicación que necesita grandes requerimientos en un nodo con recursos limitados, es posible que el nodo se quede sin memoria o recursos de la CPU y que las cosas dejen de funcionar.
También es posible que las aplicaciones tomen más recursos de los que deberían. Esto podría deberse a que un equipo genere más réplicas de las necesarias para reducir artificialmente la latencia (¡es más fácil generar más copias que hacer que su código sea más eficiente!), A un cambio de configuración incorrecto que hace que un programa salga de controlar y usar el 100% de la CPU disponible. Independientemente de si el problema está causado por un mal desarrollador, código incorrecto o mala suerte, lo importante es que no se pierda el control.
Solicitudes y límites
Las solicitudes y los límites son los mecanismos que Kubernetes usa para controlar recursos como la CPU y la memoria. Las solicitudes son lo que el contenedor está garantizado. Si un contenedor solicita un recurso, Kubernetes solo lo programará en un nodo que pueda darle ese recurso. Los límites, por otro lado, aseguran que un contenedor nunca supere un cierto valor. El contenedor solo puede subir hasta el límite y luego está restringido.
Es importante recordar que el límite nunca puede ser más bajo que la solicitud. Si prueba esto, Kubernetes arrojará un error y no le permitirá ejecutar el contenedor.
Las solicitudes y los límites son por contenedor. Los pod's pueden conetner un solo contenedor, pero es común pod's con varios contenedores. Cada contenedor del Pod's obtiene su propio límite y solicitud individual, pero como los Pods siempre se programan como un grupo, debe agregar los límites y las solicitudes de cada contenedor para obtener un valor agregado para el Pod. Para controlar qué solicitudes y límites puede tener un contenedor, puede establecer cuotas en el nivel del contenedor y en el namespaces.
Configuraciones del contenedor
Hay dos tipos de recursos: CPU y memoria. El planificador de Kubernetes los usa para averiguar dónde ejecutar tus pods. Los documentos para estos recursos. Si está ejecutando en Google Kubernetes Engine, el namespace "default" ya tiene algunas solicitudes y límites configurados.
Estas configuraciones predeterminadas son correctas para "Hello World", pero es importante cambiarlas para adaptarlas a su aplicación. Una especificación típica de Pod para recursos podría verse más o menos así. Este pod tiene dos contenedores:
Cada contenedor en el Pod puede establecer sus propias solicitudes y límites, y todos son aditivos. Por lo tanto, en el ejemplo anterior, el Pod tiene una solicitud total de 500 mCPU y 128 MiB de memoria, y un límite total de 1 CPU y 256Mib de memoria.
CPU
Los recursos de CPU se definen en milicores. Si su contenedor necesita dos núcleos completos para ejecutar, pondría el valor "2000m". Si su contenedor solo necesita ¼ de un núcleo, pondría un valor de "250 m". Una cosa a tener en cuenta acerca de las solicitudes de CPU es que si ingresas un valor mayor que el recuento de núcleos de tu nodo más grande, tu pod nunca se programará.
Digamos que tiene un pod que necesita cuatro núcleos, pero su clúster de Kubernetes está compuesto por máquinas virtuales de doble núcleo: ¡su módulo nunca se programará! A menos que su aplicación esté diseñada específicamente para aprovechar múltiples núcleos, generalmente es una buena práctica mantener la solicitud de CPU en '1' o menos y ejecutar más réplicas para escalar.
Esto le da al sistema más flexibilidad y confiabilidad. Cuando se trata de límites de CPU, las cosas se ponen interesantes. La CPU se considera un recurso "comprimible". Si su aplicación comienza a alcanzar los límites de su CPU, Kubernetes comienza a estrangular su contenedor. Esto significa que la CPU será artificialmente restringida, ¡lo que le dará a tu aplicación un peor rendimiento! Sin embargo, no se dará por terminado ni se desalojará.
Puede usar un health check Liveness para asegurarse de que el rendimiento no se haya visto afectado. Los recursos de memoria de memoria se definen en bytes. Normalmente, le da un valor mebibyte a la memoria (esto es básicamente lo mismo que un megabyte), pero puede dar cualquier cosa, desde bytes hasta petabytes.
Memoria
Al igual que la CPU, si pones una solicitud de memoria que es más grande que la cantidad de memoria en tus nodos, el pod nunca se programará. A diferencia de los recursos de la CPU, la memoria no se puede comprimir. Debido a que no hay forma de reducir el uso de memoria, si un contenedor sobrepasa su límite de memoria, terminará. Si su pod está gestionado por un "Deployment", "StatefulSet", "DaemonSe"t u otro tipo de controlador, el controlador se ejecutara solo si es posible.
Nodos
Es importante recordar que no puede establecer solicitudes que son más grandes que los recursos proporcionados por sus nodos. Por ejemplo, si tiene un clúster de máquinas de doble núcleo, ¡nunca se programará un Pod con una solicitud de 2.5 núcleos! Aquí puede encontrar los recursos totales para las VM de Kubernetes Engine.
Configuraciones de Namespace
En un mundo ideal, la configuración de contenedores de Kubernetes sería lo suficientemente buena para encargarse de todo, pero el mundo es un lugar oscuro y terrible. Las personas pueden olvidarse fácilmente de establecer los recursos, o un equipo puede establecer las solicitudes y límites muy altos y ocupar más de su parte en del clúster.
Para evitar estos escenarios, puede configurar ResourceQuotas y LimitRanges a nivel de Namespaces.
ResourceQuotas
Después de crear espacios de nombres, puede bloquearlos utilizando ResourceQuotas. Las ResourceQuotas son muy potentes, pero veamos cómo se pueden usar para restringir el uso de recursos de CPU y memoria. Una cuota para los recursos puede ser similar a esto:
Examinando este ejemplo, puede ver que hay cuatro secciones. Configurar cada una de estas secciones que es opcional.
requests.cpu es el máximo de solicitudes combinadas de CPU en millicores para todos los contenedores en el Namespace. En el ejemplo anterior, puede tener 50 contenedores con solicitudes de 10m, cinco contenedores con solicitudes de 100m o incluso un contenedor con una solicitud de 500m. ¡Siempre y cuando la CPU total solicitada en Namespace sea inferior a 500m!
requests.memory es el máximo de solicitudes combinadas de memoria para todos los contenedores en el Namespace. En el ejemplo anterior, puede tener 50 contenedores con solicitudes de 2MiB, cinco contenedores con solicitudes de CPU de 20MiB o incluso un solo contenedor con una solicitud de 100Mib. ¡Siempre y cuando la Memoria total solicitada en Namespace sea inferior a 100MiB!
limits.cpu es el límite de CPU máximo combinado para todos los contenedores en Namespace. Es como requests.cpu pero para el límite.
limits.memory es el límite máximo de Memoria combinada para todos los contenedores en Namespace. Es solo como request.memory pero para el límite. Si está utilizando un Namespaces de producción y desarrollo (a diferencia de un Namespace por equipo o servicio), un patrón común es no poner cuotas en el Namespace de producción y cuotas estrictas en Namespace de desarrollo. Esto permite que la producción tome todos los recursos que necesita en caso de un pico en el tráfico.
LimitRange
También puedes crear un LimitRange en el Namespace. A diferencia de una Cuota, que considera el Namespace como un todo, un LimitRange se aplica a un contenedor individual.
Esto puede ayudar a evitar que las personas creen contenedores súper pequeños o súper grandes dentro Namespace. Un LimitRange podría tener un aspecto similar al siguiente:
Examinando este ejemplo, puede ver que hay cuatro secciones. De nuevo, configurar cada una de estas secciones es opcional.
La sección default establece los límites predeterminados para un contenedor en un pod. Si establece estos valores en limitRange, a los contenedores que no los establezcan explícitamente se les asignarán los valores predeterminados.
La sección defaultRequest establece las solicitudes predeterminadas para un contenedor en un pod. Si establece estos valores en limitRange, a los contenedores que no los establezcan explícitamente se les asignarán los valores predeterminados.
La sección max establecerá los límites máximos que un contenedor en un Pod puede establecer. La sección predeterminada no puede ser más alta que este valor. Del mismo modo, los límites establecidos en un contenedor no pueden ser superiores a este valor. Es importante tener en cuenta que si se establece este valor y la sección predeterminada no, todos los contenedores que no establezcan explícitamente estos valores recibirán los valores máximos como límite.
La sección min establece las Solicitudes mínimas que un contenedor en un Pod puede establecer. La sección de solicitud predeterminada no puede ser menor que este valor. Del mismo modo, las solicitudes establecidas en un contenedor tampoco pueden ser inferiores a este valor. Es importante tener en cuenta que si se establece este valor y la sección defaultRequest no lo está, el valor mínimo también se convierte en el valor predeterminado de solicitud.
El lifecycle de un Pod en Kubernetes
Al final del día, el planificador Kubernetes utiliza estas solicitudes de recursos para ejecutar tus cargas de trabajo Es importante entender cómo funciona esto para que pueda ajustar sus contenedores correctamente.
Digamos que quieres ejecutar un Pod en tu Cluster. Asumiendo que las especificaciones del Pod son válidas, el planificador de Kubernetes usará el balanceo de carga round-robin para elegir un Nodo para ejecutar su carga de trabajo.
Nota: La excepción a esto es si usa un nodeSelector o mecanismo similar para forzar a Kubernetes a programar su Pod en un lugar específico. Las verificaciones de recursos aún ocurren cuando usa un nodeSelector, pero Kubernetes solo verificará los nodos que tengan la etiqueta requerida.
Kubernetes luego verifica si el Nodo tiene suficientes recursos para cumplir con las solicitudes de recursos en los contenedores del Pod. Si no lo hace, pasa al siguiente nodo. Si ninguno de los Nodos en el sistema tiene recursos para completar las solicitudes, los Pods entran en un estado "pendiente".
Al utilizar las características de Kubernetes Engine, como el Node Autoscaler, Kubernetes Engine puede detectar automáticamente este estado y crear más Nodos automáticamente. Si hay un exceso de capacidad, el escalador automático también puede escalar y eliminar nodos para ahorrar dinero.
Pero, ¿qué pasa con los límites? Como sabe, los límites pueden ser más altos que las solicitudes. ¿Qué sucede si tiene un Nodo donde la suma de todos los Límites del contenedor es en realidad más alta que los recursos disponibles en la máquina? En este punto, Kubernetes entra en algo llamado "estado comprometido".
Aquí es donde las cosas se ponen interesantes. Debido a que la CPU se puede comprimir, Kubernetes se asegurará de que sus contenedores obtengan la CPU que solicitaron y estrangulará el resto. La memoria no se puede comprimir, por lo que Kubernetes necesita comenzar a tomar decisiones sobre qué contenedores terminar si el Nodo se queda sin memoria.
Imaginemos un escenario en el que tenemos una máquina que se está quedando sin memoria. ¿Qué hará Kubernetes?
Nota: Lo siguiente es cierto para Kubernetes 1.9 y superior. En versiones anteriores, utiliza un proceso ligeramente diferente. Vea este documento para una explicación detallada.
Kubernetes busca Pods que estén usando más recursos de los que solicitaron. Si los contenedores de su Pod no tienen solicitudes, entonces, de forma predeterminada, están utilizando más de lo solicitado, por lo que estos son los principales candidatos para la terminación.
Otros candidatos principales son los contenedores que han revisado su solicitud, pero aún están por debajo de su límite. Si Kubernetes encuentra varios pods que han revisado sus solicitudes, los clasificará según la prioridad del Pod y terminará primero con los pods de prioridad más baja.
Si todos los Pods tienen la misma prioridad, Kubernetes termina el Pod que es más sobre su solicitud.
En escenarios muy raros, Kubernetes podría verse obligado a terminar Pods que todavía están dentro de sus solicitudes. Esto puede suceder cuando los componentes críticos del sistema, como el kubelet o el docker, comienzan a tomar más recursos de los que estaban reservados para ellos.
Conclusión
Si bien su clúster de Kubernetes podría funcionar bien sin establecer límites y solicitudes de recursos, comenzará a tener problemas de estabilidad a medida que crezcan sus equipos y proyectos. ¡Agregar solicitudes y límites a sus Pods y Namespaces solo requiere un pequeño esfuerzo adicional, y puede evitar que sufra muchos dolores de cabeza más adelante!
Con este artículo quiero poner
mi granito de arena a todo aquel profesional que esté interesado en la
obtención de la certificación de Google Cloud Architect, por lo que me gustaría
explicaros mi experiencia de como es el examen y que preparación seguí para
obtener la certificación.
Antes de empezar, me gustaría apuntar que esta certificación aglutina distintas tecnologías con las que no
todos los profesionales trabajamos en nuestro día a día. Por mi parte tuve que
hacer hincapié en algunas de las áreas donde no me sentía tan cómodo, las
cuales variarán según la
experiencia de cada uno.
Dispones de 2h para realizar el examen, que consta de 50 preguntas tipo
test de las cuales unas 20 están basadas en unos de los casos de estudio que te puedes preparar previamente. (En mi caso
fueron 3).
Las preguntas son de razonamiento, por lo que no requieren memorizar datos,
sino conocer el portfolio de servicios y ver cual encaja mejor en la solución.
Considero que es un examen que aunque tuvieras acceso al buscador de Google,
tendrías que trabajártelo.
Recomiendo leerse con detalle cada pregunta y saber qué te están pidiendo exactamente, luego ir descartando las menos
posibles hasta quedarnos con la más idónea para ese escenario. En algunas de
ellas encontré dos opciones factibles, y acabe decantándome por un razonamiento
más comercial que técnico.
Por otra parte me encontré algunas preguntas que requerían de algo de
experiencia no solo en el entorno Google Cloud, como migraciones de entornos de
base de datos, o identificar problemas de código.
No tengo claro el porcentaje de aprobado del examen, leí que necesitabas un
80% de respuestas correctas y un 10% de ellas computaban de una manera
diferente.
Al finalizar teindican pass\fail y
no te dan más información, para saber dónde has fallado y en que poder mejorar.
Como preparación al examen hice una adaptación dela guía de examen, la cual os detallo a continuación:
Me cree una
cuenta gratuita de GCP
Revisé los vídeos de GDG Cloud Español y
realicé cada uno de los escenarios.
Realicé varias formaciones on-line para tener
una buena base en dockers, kubernetes y python.
Me documenté
sobre cómo funcionan las ETL, Analítica
de datos, ML…
Hice la
formación íntegra de coursera y resumí
cada uno de los temas.
Tuve la
suerte de asistir al Google Cloud On Board. En su defecto, podéis ver alguno de los eventos que
podréis encontrar en la red.
Una vez acabada la preparación de forma genérica, me centré en conocer bien
todos los elementos de la plataforma, recomendando prestar especial atención a los siguientes puntos:
Conocer
el funcionamiento de Machine Learning, para
ello aconsejo leerse el
siguiente artículo.
Los últimos días antes del examen me centré en aprenderme los casos de estudio y buscar qué
soluciones se aplicarían en cada uno de ellos, además de realizar el examen de
práctica que ofrece
Google y hacer los test de Joseph
Holbrook mediante
el portal de Udemy, que aunque no sean oficiales me ayudaron a asimilar muchos
conceptos y practicar la dinámica del examen.
Este viernes Sandeep Dinesh, Google Developer Advocate, no ha faltado a si cita de kubernetes Best practices y como no aquí lo tenéis en google cloud español.
Los sistemas distribuidos pueden ser difíciles de administrar. Hay mucho codigo que cambia y esta en mantenimiento. Si se rompe una parte pequeña, el sistema tiene que detectarla, enrutarla y arreglarla. ¡Y todo esto debe hacerse automáticamente!
Los controles de estad, a partir de ahora health checks son una forma sencilla de informar al sistema si una instancia de su aplicación está funcionando o no funciona. Si una instancia de su aplicación no funciona, entonces otros servicios no deberían acceder a ella o enviarle una solicitud. En su lugar, las solicitudes se deben enviar a otra instancia de la aplicación que esté lista o que se vuelva a intentar en otro momento. El sistema también debería devolver tu aplicación a un health OK .
De manera predeterminada, Kubernetes comienza a enviar tráfico a un pod cuando se inician todos los contenedores dentro del pod y reinicia los contenedores cuando se cuelgan. Si bien esto puede ser "lo suficientemente bueno" cuando está comenzando, puede hacer que sus implementaciones sean más robustas mediante la creación de controles de estado personalizados. Afortunadamente, Kubernetes lo hace relativamente sencillo, ¡así que no hay excusa para no hacerlo!
En este episodio de "Mejores prácticas de Kubernetes", aprendamos sobre la manera de las sondas de de crear sondas de estado, y cuándo usar qué sonda y cómo configurarlas en su clúster de Kubernetes.
Tipos de health checks
Kubernetes le ofrece dos tipos de controles de salud, y es importante comprender las diferencias entre los dos y sus usos.
Readiness
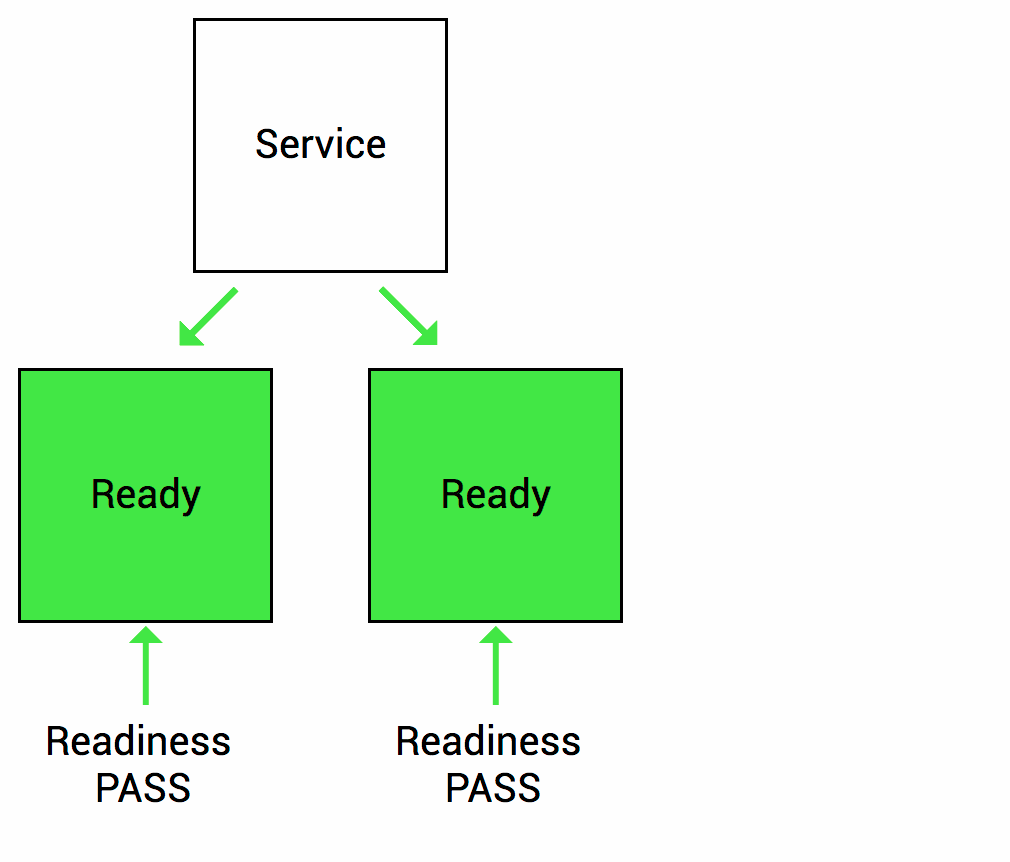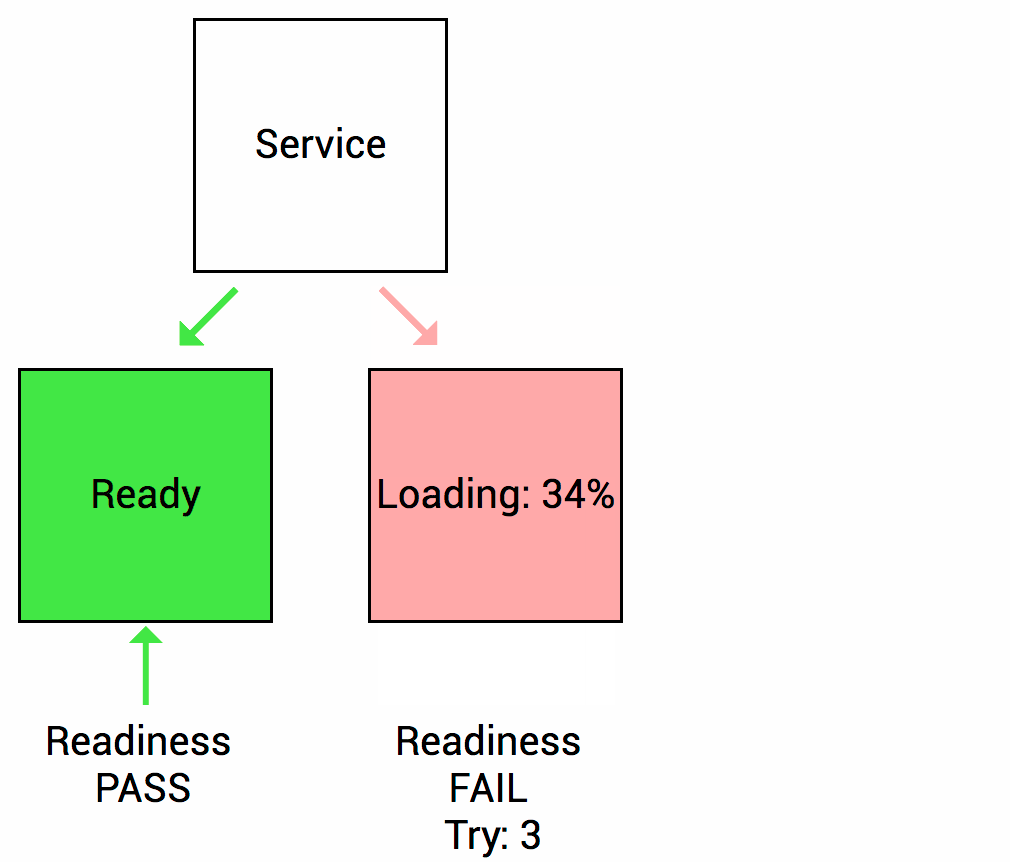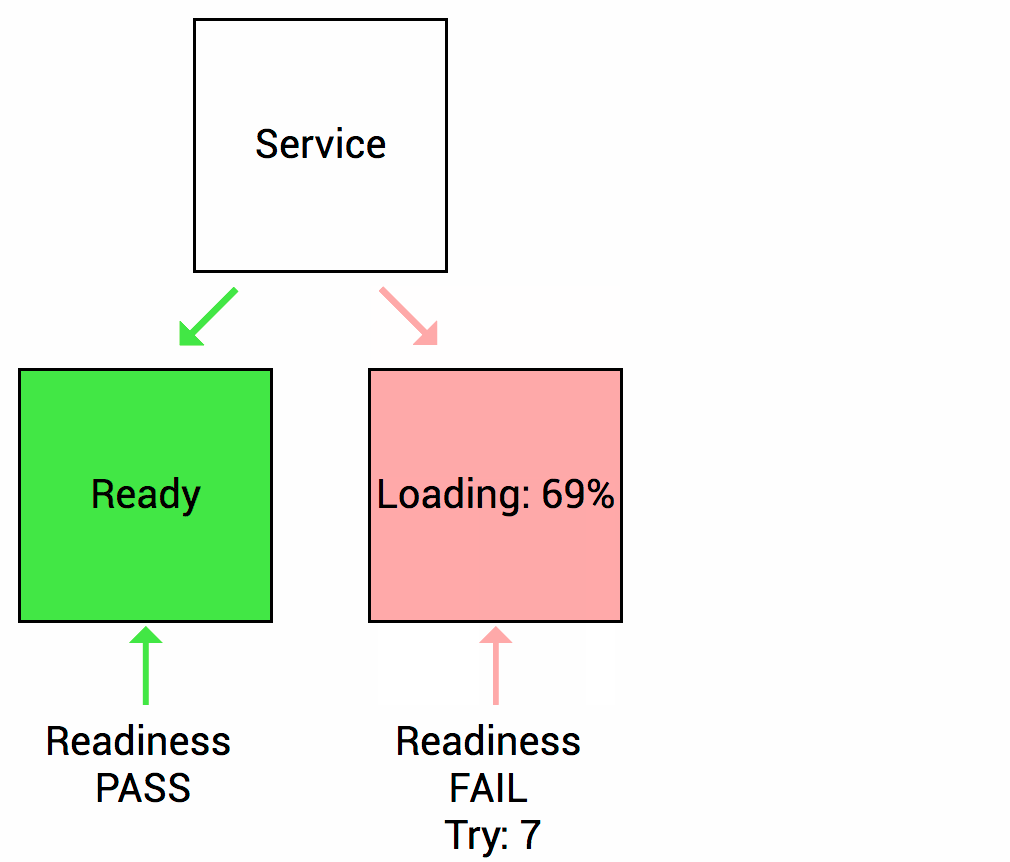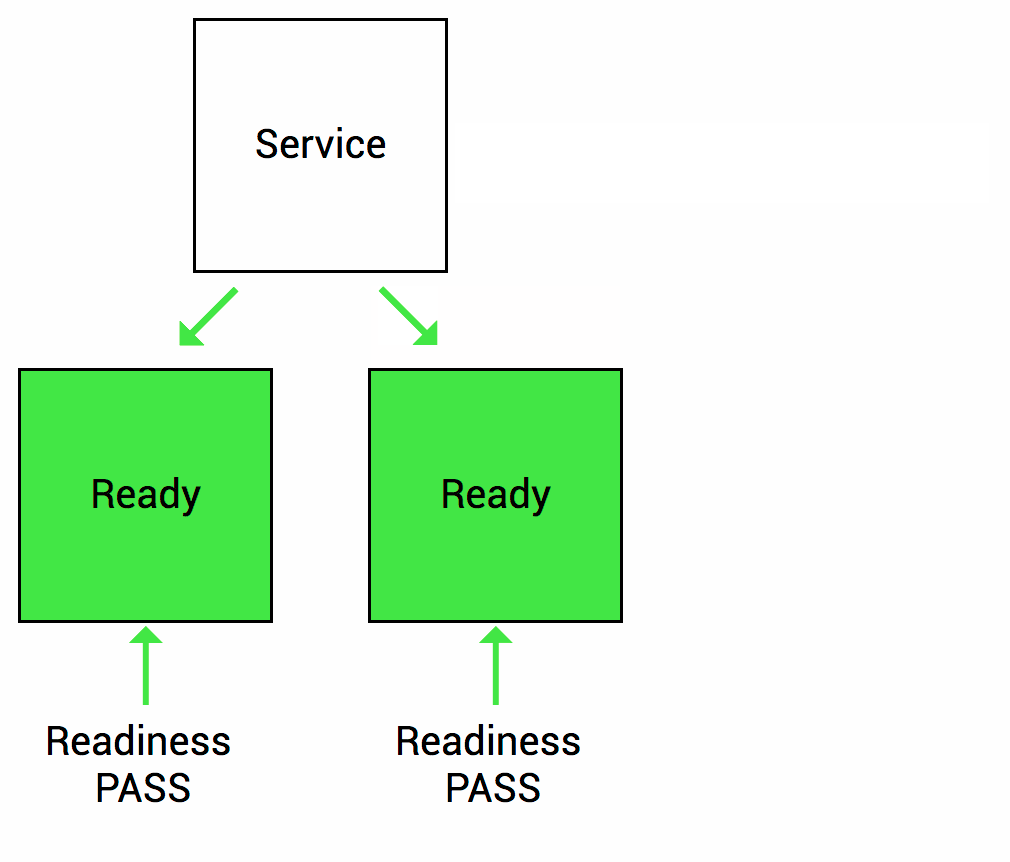
Las sondas de readiness están diseñadas para informar a Kubernetes cuando su aplicación está lista para servir el tráfico. Kubernetes se asegura de que la sonda de readiness pase antes de permitir que un servicio envíe tráfico al pod. Si una sonda de preparación comienza a fallar, Kubernetes deja de enviar tráfico a la cápsula hasta que pasa.
Liveness
Las sondas de Liveness le informan a Kubernetes si su aplicación está viva o muerta. Si tu aplicación está viva, Kubernetes la deja sola. Si su aplicación está muerta, Kubernetes elimina el Pod y comienza una nueva para reemplazarlo.
Cómo ayuda un health checks
Veamos dos escenarios en los que las sondas de readiness y lveness pueden ayudarlo a crear una aplicación más sólida.
Readiness
Imaginemos que su aplicación tarda un minuto en arrancar y comenzar. Su servicio no funcionará hasta que esté en funcionamiento, aunque el proceso haya comenzado. También tendrá problemas si desea ampliar esta implementación para tener múltiples copias. Una copia nueva no debe recibir tráfico hasta que esté completamente lista, pero Kubernetes comienza a enviar el tráfico de manera predeterminada en cuanto comienza el proceso dentro del contenedor. Al usar una sonda de readiness, Kubernetes espera hasta que la aplicación se haya iniciado completamente antes de permitir que el servicio envíe tráfico a la nueva copia.
Liveness
Imaginemos otro escenario en el que su aplicación tenga un problema, un caso de punto muerto, lo que hará que se cuelgue indefinidamente y deje de atender solicitudes. Debido a que el proceso continúa ejecutándose, Kubernetes piensa de manera predeterminada que todo está bien y continúa enviando solicitudes al pod roto. Mediante el uso de una sonda de liveness, Kubernetes detecta que la aplicación ya no está atendiendo solicitudes y reinicia el pod corrupto.
Tipo de sondas
El siguiente paso es definir las sondas que prueban la readiness y la liveness. Hay tres tipos de sondeos: HTTP, Comando y TCP. Puede usar cualquiera de ellos para comprobar su liveness y readiness.
HTTP
Las sondas HTTP son probablemente el tipo más común de health checks personalizada. Incluso si su aplicación no es un servidor HTTP, puede crear un servidor HTTP liviano dentro de su aplicación para responder al sondeo de liveness. Kubernetes marca un camino, y si obtiene una respuesta HTTP en el rango 200 o 300, marca la aplicación como saludable. De lo contrario, está marcado como caido.
Para las sondas de comando, Kubernetes ejecuta un comando dentro de su contenedor. Si el comando regresa con el código de salida 0, entonces el contenedor se marca como correcto. De lo contrario, está marcado como caido. Este tipo de sonda es útil cuando no puede o no quiere ejecutar un servidor HTTP, pero puede ejecutar un comando que puede verificar si su aplicación está sana o no.
El último tipo de sonda es la sonda TCP, donde Kubernetes intenta establecer una conexión TCP en el puerto especificado. Si puede establecer una conexión, el contenedor se considera saludable; si no puede, se considera insalubre.
Las sondas TCP son útiles si tiene un escenario donde las sondas HTTP o la sonda de comando no funcionan bien. Por ejemplo, un servicio gRPC o FTP es un candidato ideal para este tipo de check.
Las sondas se pueden configurar de muchas maneras. Puede especificar con qué frecuencia deben ejecutarse, cuáles son los umbrales de éxito y falla y cuánto esperar para obtener respuestas. La documentación sobre la configuración de las sondas es bastante clara sobre las diferentes opciones y lo que hacen.
Sin embargo, hay una configuración muy importante que debe configurar cuando usa sondas de health. Esta es la configuración initialDelaySeconds.
Como mencioné anteriormente, una error en la health check hace que el pod se reinicie. Debe asegurarse de que la sonda no se inicie hasta que la aplicación esté lista. De lo contrario, la aplicación se reiniciará constantemente y ¡nunca estará listo!
Recomiendo usar el tiempo de inicio p99 como initialDelaySeconds, o simplemente tomar el tiempo promedio de inicio y agregar un búfer. A medida que el tiempo de inicio de la aplicación se vuelve más rápido o más lento, asegúrese de actualizar este número.
Conclusión
La mayoría de las personas le dirá que los health checks son un requisito para cualquier sistema distribuido, y Kubernetes no es una excepción. El uso de controles de estado le brinda a sus servicios de Kubernetes una base sólida, una mayor confiabilidad y un mayor tiempo de actividad. Afortunadamente, ¡Kubernetes lo hace fácil de configurar!