

Este viernes Sandeep Dinesh, Google Developer Advocate, no ha faltado a si cita de kubernetes Best practices y como no aquí lo tenéis en google cloud español.
Los sistemas distribuidos pueden ser difíciles de administrar. Hay mucho codigo que cambia y esta en mantenimiento. Si se rompe una parte pequeña, el sistema tiene que detectarla, enrutarla y arreglarla. ¡Y todo esto debe hacerse automáticamente!
Los controles de estad, a partir de ahora health checks son una forma sencilla de informar al sistema si una instancia de su aplicación está funcionando o no funciona. Si una instancia de su aplicación no funciona, entonces otros servicios no deberían acceder a ella o enviarle una solicitud. En su lugar, las solicitudes se deben enviar a otra instancia de la aplicación que esté lista o que se vuelva a intentar en otro momento. El sistema también debería devolver tu aplicación a un health OK .
De manera predeterminada, Kubernetes comienza a enviar tráfico a un pod cuando se inician todos los contenedores dentro del pod y reinicia los contenedores cuando se cuelgan. Si bien esto puede ser "lo suficientemente bueno" cuando está comenzando, puede hacer que sus implementaciones sean más robustas mediante la creación de controles de estado personalizados. Afortunadamente, Kubernetes lo hace relativamente sencillo, ¡así que no hay excusa para no hacerlo!
En este episodio de "Mejores prácticas de Kubernetes", aprendamos sobre la manera de las sondas de de crear sondas de estado, y cuándo usar qué sonda y cómo configurarlas en su clúster de Kubernetes.
Tipos de health checks
Kubernetes le ofrece dos tipos de controles de salud, y es importante comprender las diferencias entre los dos y sus usos.
Readiness
Las sondas de readiness están diseñadas para informar a Kubernetes cuando su aplicación está lista para servir el tráfico. Kubernetes se asegura de que la sonda de readiness pase antes de permitir que un servicio envíe tráfico al pod. Si una sonda de preparación comienza a fallar, Kubernetes deja de enviar tráfico a la cápsula hasta que pasa.
Liveness
Las sondas de Liveness le informan a Kubernetes si su aplicación está viva o muerta. Si tu aplicación está viva, Kubernetes la deja sola. Si su aplicación está muerta, Kubernetes elimina el Pod y comienza una nueva para reemplazarlo.
Cómo ayuda un health checks
Veamos dos escenarios en los que las sondas de readiness y lveness pueden ayudarlo a crear una aplicación más sólida.
Readiness
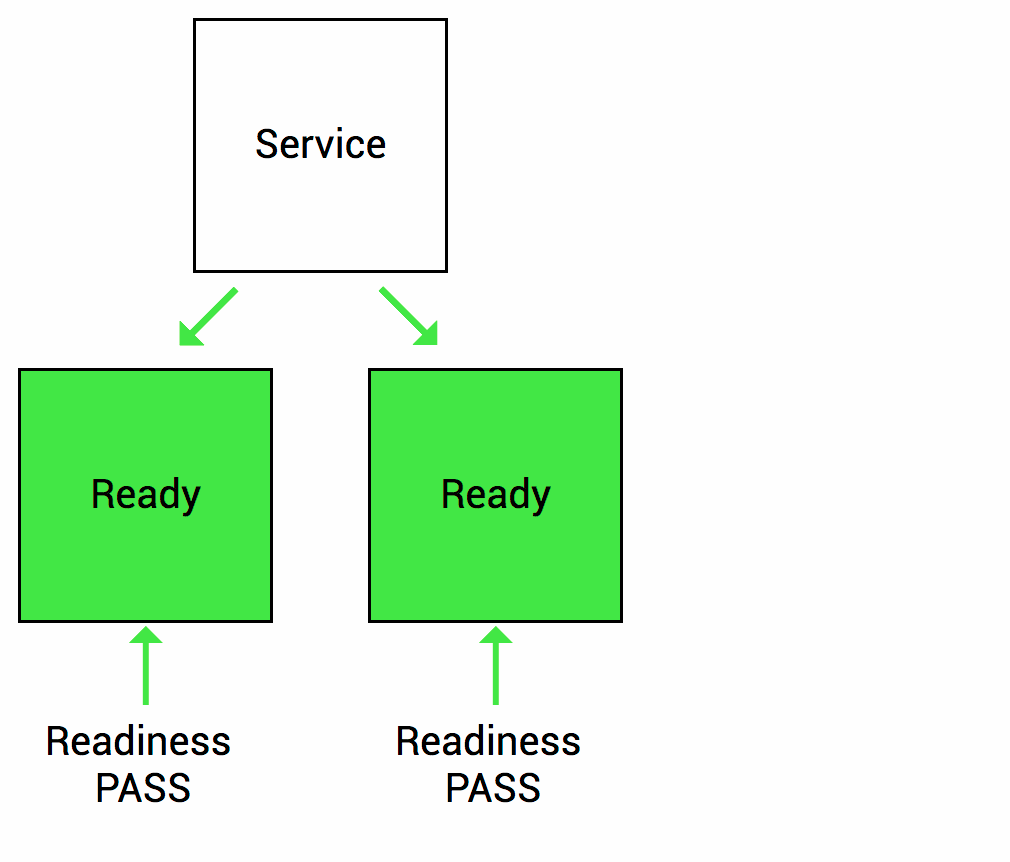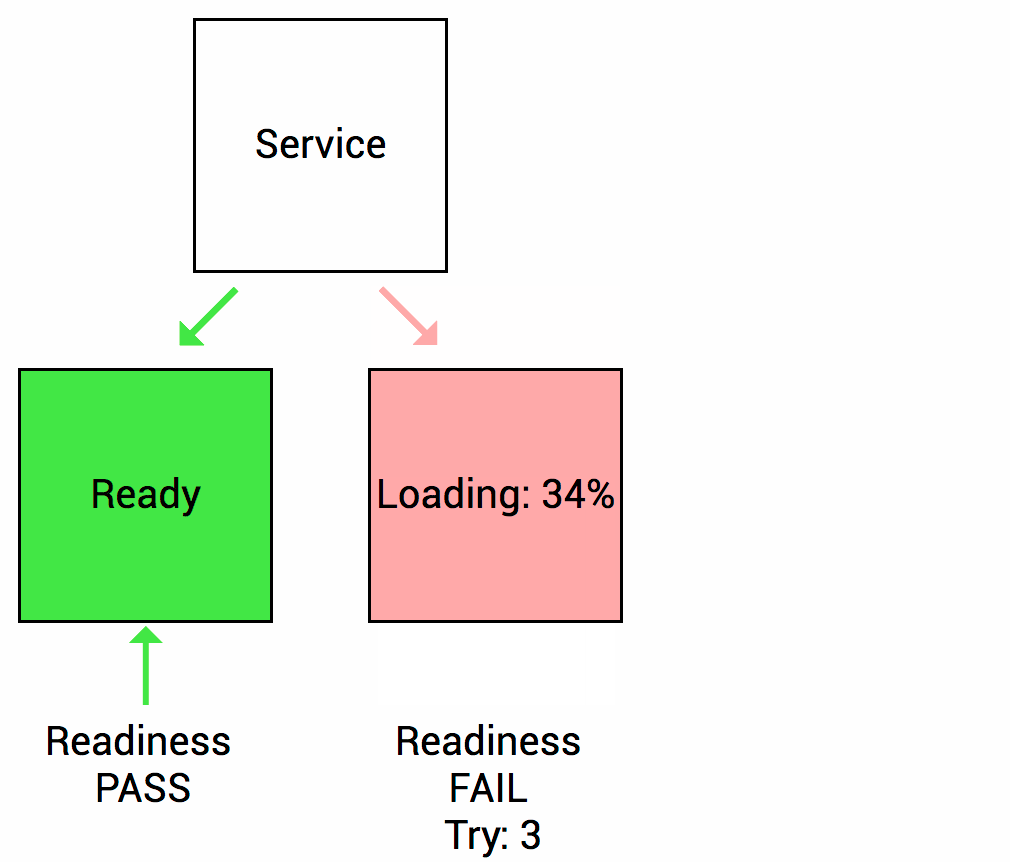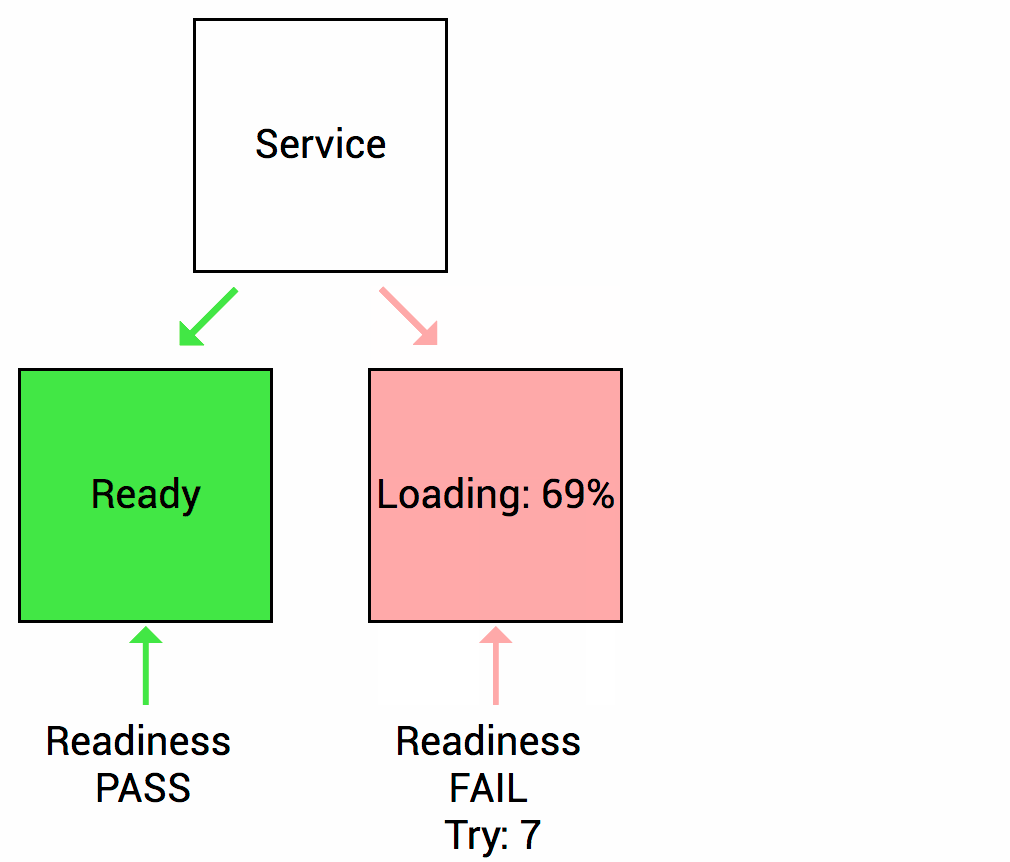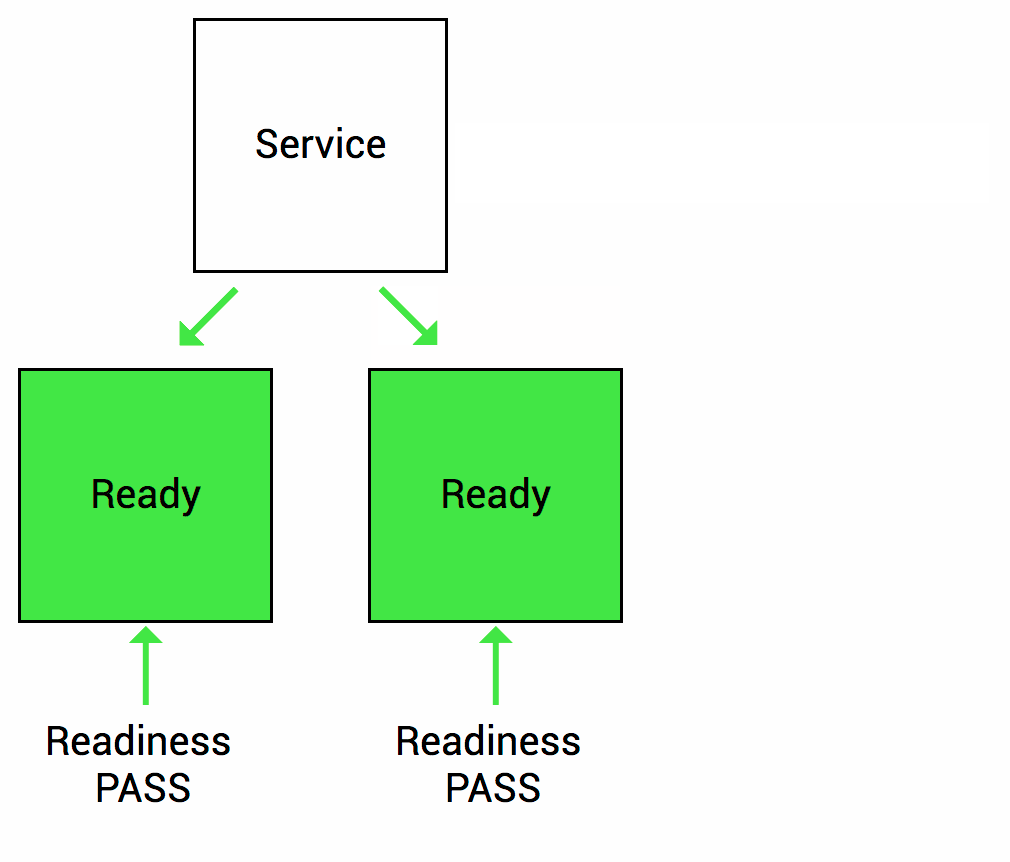
Imaginemos que su aplicación tarda un minuto en arrancar y comenzar. Su servicio no funcionará hasta que esté en funcionamiento, aunque el proceso haya comenzado. También tendrá problemas si desea ampliar esta implementación para tener múltiples copias. Una copia nueva no debe recibir tráfico hasta que esté completamente lista, pero Kubernetes comienza a enviar el tráfico de manera predeterminada en cuanto comienza el proceso dentro del contenedor. Al usar una sonda de readiness, Kubernetes espera hasta que la aplicación se haya iniciado completamente antes de permitir que el servicio envíe tráfico a la nueva copia.
Liveness
Imaginemos otro escenario en el que su aplicación tenga un problema, un caso de punto muerto, lo que hará que se cuelgue indefinidamente y deje de atender solicitudes. Debido a que el proceso continúa ejecutándose, Kubernetes piensa de manera predeterminada que todo está bien y continúa enviando solicitudes al pod roto. Mediante el uso de una sonda de liveness, Kubernetes detecta que la aplicación ya no está atendiendo solicitudes y reinicia el pod corrupto.

Tipo de sondas
El siguiente paso es definir las sondas que prueban la readiness y la liveness. Hay tres tipos de sondeos: HTTP, Comando y TCP. Puede usar cualquiera de ellos para comprobar su liveness y readiness.
HTTP
Las sondas HTTP son probablemente el tipo más común de health checks personalizada. Incluso si su aplicación no es un servidor HTTP, puede crear un servidor HTTP liviano dentro de su aplicación para responder al sondeo de liveness. Kubernetes marca un camino, y si obtiene una respuesta HTTP en el rango 200 o 300, marca la aplicación como saludable. De lo contrario, está marcado como caido.
Puede leer más sobre las sondas HTTP aquí.
Comando
Para las sondas de comando, Kubernetes ejecuta un comando dentro de su contenedor. Si el comando regresa con el código de salida 0, entonces el contenedor se marca como correcto. De lo contrario, está marcado como caido. Este tipo de sonda es útil cuando no puede o no quiere ejecutar un servidor HTTP, pero puede ejecutar un comando que puede verificar si su aplicación está sana o no.
Puede leer más sobre las sondas de comando aquí.
TCP
El último tipo de sonda es la sonda TCP, donde Kubernetes intenta establecer una conexión TCP en el puerto especificado. Si puede establecer una conexión, el contenedor se considera saludable; si no puede, se considera insalubre.
Las sondas TCP son útiles si tiene un escenario donde las sondas HTTP o la sonda de comando no funcionan bien. Por ejemplo, un servicio gRPC o FTP es un candidato ideal para este tipo de check.
Puede leer más sobre las sondas TCP aquí.
Configurar el retraso de sondeo inicial
Las sondas se pueden configurar de muchas maneras. Puede especificar con qué frecuencia deben ejecutarse, cuáles son los umbrales de éxito y falla y cuánto esperar para obtener respuestas. La documentación sobre la configuración de las sondas es bastante clara sobre las diferentes opciones y lo que hacen.
Sin embargo, hay una configuración muy importante que debe configurar cuando usa sondas de health. Esta es la configuración initialDelaySeconds.
Como mencioné anteriormente, una error en la health check hace que el pod se reinicie. Debe asegurarse de que la sonda no se inicie hasta que la aplicación esté lista. De lo contrario, la aplicación se reiniciará constantemente y ¡nunca estará listo!
Recomiendo usar el tiempo de inicio p99 como initialDelaySeconds, o simplemente tomar el tiempo promedio de inicio y agregar un búfer. A medida que el tiempo de inicio de la aplicación se vuelve más rápido o más lento, asegúrese de actualizar este número.
Conclusión
La mayoría de las personas le dirá que los health checks son un requisito para cualquier sistema distribuido, y Kubernetes no es una excepción. El uso de controles de estado le brinda a sus servicios de Kubernetes una base sólida, una mayor confiabilidad y un mayor tiempo de actividad. Afortunadamente, ¡Kubernetes lo hace fácil de configurar!
No hay comentarios:
Publicar un comentario
Nota: solo los miembros de este blog pueden publicar comentarios.