

Tal vez estés ejecutando una consulta en BigQuery y descargando los resultados en BigTable cada mañana para realizar un análisis. O quizás necesite actualizar los datos en una tabla dinámica en Google Sheets para crear un histograma para mostrar sus datos de facturación. En cualquier caso, a nadie le gusta hacer lo mismo todos los días si la tecnología puede hacerlo por ti. ¡Contempla la magia de Cloud Scheduler, Cloud Functions y PubSub!
Cloud Scheduler es un producto administrado de Google Cloud Platform (GCP) que te permite especificar una frecuencia para programar un trabajo recurrente. En pocas palabras, es un planificador de tareas gestionado ligero. Esta tarea puede ser un trabajo por lotes ad hoc, un trabajo de procesamiento de big data, herramientas de automatización de infraestructura, lo que sea. Lo bueno es que Cloud Scheduler se encarga de todo el trabajo ademas se reintenta en caso de fallo e incluso le permite ejecutar algo a las 4 AM, para que no tenga que despertarse en medio de la noche para correr una carga de trabajo en otro momento fuera de hora punta.
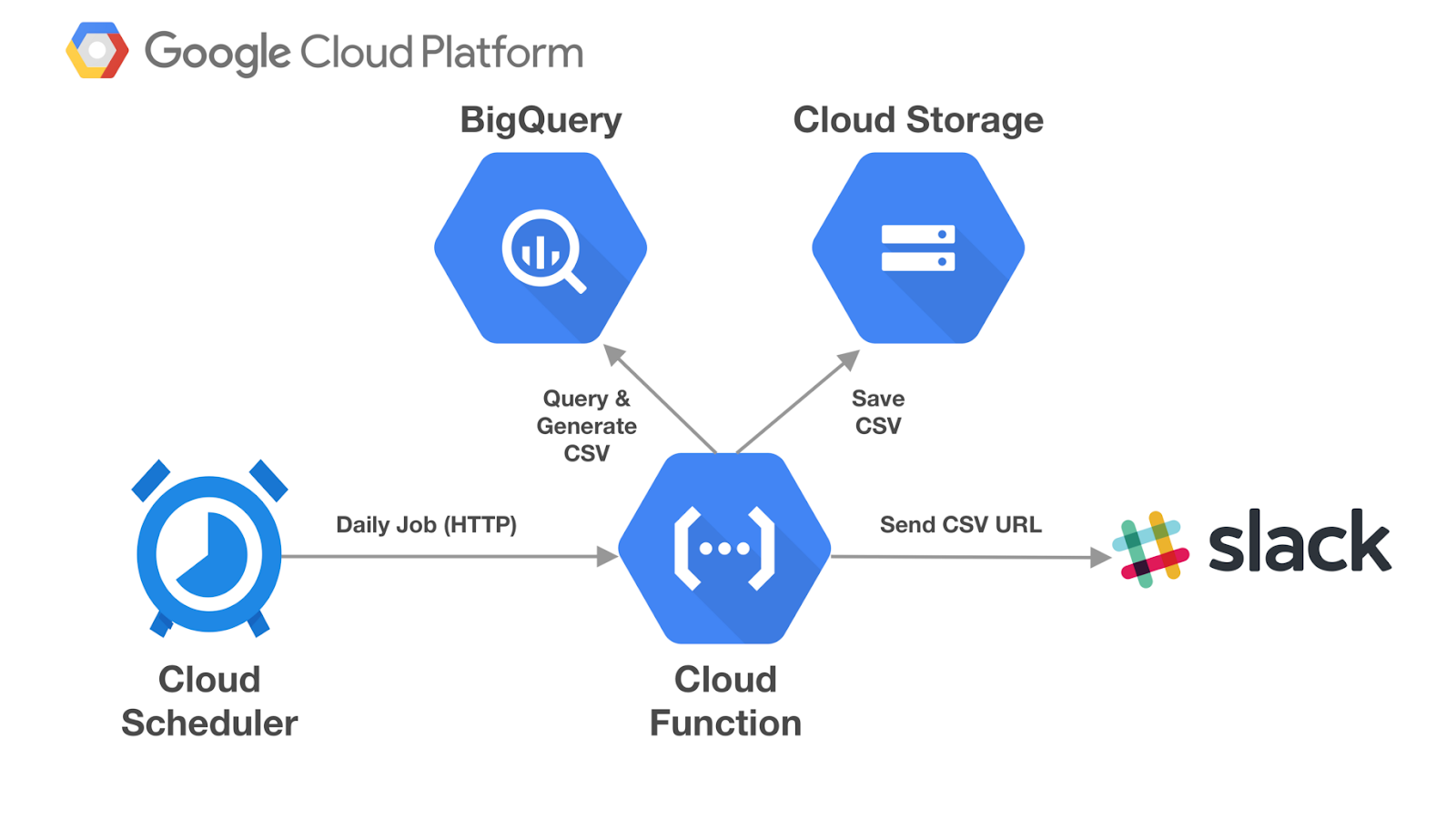
Al configurar el trabajo, puedes determinar qué exactamente "disparará" en un momento concreto Puede tratarse de un publicación en un PubSub, o un end-point de HTTP o una aplicación App Engine. En este ejemplo, publicaremos un mensaje a un tema de PubSub.
Nuestro tema de PubSub existe únicamente para conectar los dos extremos de nuestra canalización: es un mecanismo intermediario para conectar el trabajo de Cloud Scheduler y la función en cloud que contiene la secuencia de comandos de Python real que ejecutaremos. Esencialmente, el tema de PubSub actúa como una línea telefónica, proporcionando la conexión que permite que el trabajo del Programador del cloud hable y la Función de la Nube para escuche. Esto se debe a que el trabajo de Cloud Scheduler publica un mensaje al tema. La función de nube se suscribe a este tema. Esto significa que se alerta cuando se publica un nuevo mensaje. Cuando recibe una alerta, ejecuta el script de Python.
The Code
SQL
Para este ejemplo, mostraré un script de Python simple que quiero ejecutar diariamente a las 8 AM y las 8 PM . El script es básico: ejecuta una consulta SQL en BigQuery para encontrar los repositorios populares de Github. Buscaremos específicamente qué propietarios crearon repositorios con la mayor cantidad de contenedores y en qué año se crearon. Usaremos datos del conjunto de datos público bigquery-public-data: sample, que contiene datos sobre los repositorios creados entre 2007 y 2012.
Nuestra consulta SQL tiene este aspecto:
Paso 1: asegúrese de tener Python 3 e instale e inicialice el SDK de google cloud. Lo siguiente les una guia a través de cómo crear el entorno GCP. Si desea probarlo localmente, asegúrese de haber seguido primero las instrucciones para configurar Python 3 en GCP.
Paso 2: crea un archivo llamado requirements.txt y copia y pega lo siguiente:
Paso 4: Cree un archivo llamado config.py y edítelo con sus valores para las siguientes variables.
Puede usar un conjunto de datos existente para esto o elegir un ID de un nuevo conjunto de datos que creará, solo recuerde el ID ya que lo necesitará para otorgar permisos más adelante.
La creación de un tema de PubSub con un nombre de su elección y la especificación de que esta función se activa cada vez que se publica un nuevo mensaje sobre este tema. También esta establecido el tiempo de espera al máximo que GCP ofrece de 540 segundos o nueve minutos.
Especifica la frecuencia con la que se ejecutará la función de la nube en el tiempo cron de UNIX al configurar el programador del Cloud con el indicador de programación. Esto significa que publicará un mensaje al tema de PubSub cada 12 horas en la zona horaria UTC, como se ve a continuación:
Nuestro código de Python no usa el mensaje real. ¡Este es un trabajo que ejecuto dos veces por día! "" Publicado en el tema porque solo estamos ejecutando una consulta en BigQuery, pero vale la pena señalar que puede recuperar este mensaje y actuar. tal, como para fines de registro o de otro tipo.
Conceder permisos
Finalmente, abra la interfaz de usuario de BigQuery y haga clic en "Crear conjunto de datos" en el proyecto al que hizo referencia anteriormente.
Al crear la Función de la nube, creó una cuenta de servicio con el correo electrónico en el formato [PROJECT_ID] @ appspot.gserviceaccount.com. Copia este correo electrónico para el siguiente paso.
Pase el cursor sobre el ícono Más para este nuevo conjunto de datos.
Haga clic en "Compartir conjunto de datos".
En la ventana emergente, ingrese el correo electrónico de la cuenta de servicio. Dale permiso "Can Edit".
Ejecutar el trabajo:
Puede probar el flujo de trabajo anterior ejecutando el proyecto ahora, en lugar de esperar la hora programada de UNIX. Para hacer esto:
Para obtener más información, lea nuestra documentación sobre la configuración de Cloud Scheduler con PubSub trigger y pruébelo utilizando uno de nuestros conjuntos de datos públicos de BigQuery.
Nuestra consulta SQL tiene este aspecto:
SELECTSUM(repository.forks) AS sum_forks,repository.owner,EXTRACT(YEAR FROM PARSE_TIMESTAMP('%Y/%m/%d %H:%M:%S %z', repository.created_at)) AS year_createdFROM`bigquery-public-data.samples.github_nested`WHERErepository.created_at IS NOT NULLGROUP BY2,3ORDER BY3 DESC
Python
Pronto pegaremos esta consulta en nuestro archivo github_query.sql. Esto se llamará en nuestro archivo main.py, que llama a una función principal que ejecuta la consulta en Python mediante el uso de Python Client Library para BigQuery.Paso 1: asegúrese de tener Python 3 e instale e inicialice el SDK de google cloud. Lo siguiente les una guia a través de cómo crear el entorno GCP. Si desea probarlo localmente, asegúrese de haber seguido primero las instrucciones para configurar Python 3 en GCP.
Paso 2: crea un archivo llamado requirements.txt y copia y pega lo siguiente:
google-cloud-bigquery
Paso 3: Crea un archivo llamado github_query.sql y pega en la consulta SQL desde arriba.Paso 4: Cree un archivo llamado config.py y edítelo con sus valores para las siguientes variables.
Puede usar un conjunto de datos existente para esto o elegir un ID de un nuevo conjunto de datos que creará, solo recuerde el ID ya que lo necesitará para otorgar permisos más adelante.
Paso 4: Cree un archivo llamado main.py que haga referencia a los dos archivos anteriores.config_vars = {'project_id': [ENTER YOUR PROJECT ID HERE],'output_dataset_id': '[ENTER OUTPUT DATASET HERE]','output_table_name': '[ENTER OUTPUT TABLE NAME HERE]','sql_file_path': 'github_query.sql'}
Para implementar la función en GCP, puede ejecutar los siguientes comandos de gcloud. Esto especifica el uso de un tiempo de ejecución de Python 3.7,"""Function called by PubSub trigger to execute cron job tasks."""import datetimeimport loggingfrom string import Templateimport configfrom google.cloud import bigquerydef file_to_string(sql_path):"""Converts a SQL file holding a SQL query to a string.Args:sql_path: String containing a file pathReturns:String representation of a file's contents"""with open(sql_path, 'r') as sql_file:return sql_file.read()def execute_query(bq_client):"""Executes transformation query to a new destination table.Args:bq_client: Object representing a reference to a BigQuery Client"""dataset_ref = bq_client.get_dataset(bigquery.DatasetReference(project=config.config_vars['project_id'],dataset_id=config.config_vars['output_dataset_id']))table_ref = dataset_ref.table(config.config_vars['output_table_name'])job_config = bigquery.QueryJobConfig()job_config.destination = table_refjob_config.write_disposition = bigquery.WriteDisposition().WRITE_TRUNCATEsql = file_to_string(config.config_vars['sql_file_path'])logging.info('Attempting query on all dates...')# Execute Queryquery_job = bq_client.query(sql,job_config=job_config)query_job.result() # Waits for the query to finishlogging.info('Query complete. The table is updated.')def main(data, context):"""Triggered from a message on a Cloud Pub/Sub topic.Args:data (dict): Event payload.context (google.cloud.functions.Context): Metadata for the event."""bq_client = bigquery.Client()try:current_time = datetime.datetime.utcnow()log_message = Template('Cloud Function was triggered on $time')logging.info(log_message.safe_substitute(time=current_time))try:execute_query(bq_client)except Exception as error:log_message = Template('Query failed due to ''$message.')logging.error(log_message.safe_substitute(message=error))except Exception as error:log_message = Template('$error').substitute(error=error)logging.error(log_message)if __name__ == '__main__':main('data', 'context')
La creación de un tema de PubSub con un nombre de su elección y la especificación de que esta función se activa cada vez que se publica un nuevo mensaje sobre este tema. También esta establecido el tiempo de espera al máximo que GCP ofrece de 540 segundos o nueve minutos.
Asegúrese de que primero cd en el directorio donde se encuentran los archivos antes de la implementación, de lo contrario no funcionará lo siguiente.gcloud functions deploy [FUNCTION_NAME] --entry-point main --runtime python37 --trigger-resource [TOPIC_NAME] --trigger-event google.pubsub.topic.publish --timeout 540s
Especifica la frecuencia con la que se ejecutará la función de la nube en el tiempo cron de UNIX al configurar el programador del Cloud con el indicador de programación. Esto significa que publicará un mensaje al tema de PubSub cada 12 horas en la zona horaria UTC, como se ve a continuación:
donde [JOB_NAME] es un nombre único para un trabajo, [SCHEDULE] es la frecuencia para el trabajo en UNIX cron, como "0 * / 12 * * *" para ejecutar cada 12 horas, [TOPIC_NAME] es el nombre del tema creado en el paso anterior cuando implementó la función de nube, y [MESSAGE_BODY] es cualquier cadena. Un ejemplo de comando sería:gcloud scheduler jobs create pubsub [JOB_NAME] --schedule [SCHEDULE] --topic [TOPIC_NAME] --message-body [MESSAGE_BODY]
gcloud scheduler jobs create pubsub daily_job --schedule "0 */12 * * *" --topic my-pubsub-topic --message-body "This is a job that I run twice per day!"Nuestro código de Python no usa el mensaje real. ¡Este es un trabajo que ejecuto dos veces por día! "" Publicado en el tema porque solo estamos ejecutando una consulta en BigQuery, pero vale la pena señalar que puede recuperar este mensaje y actuar. tal, como para fines de registro o de otro tipo.
Conceder permisos
Finalmente, abra la interfaz de usuario de BigQuery y haga clic en "Crear conjunto de datos" en el proyecto al que hizo referencia anteriormente.
Al crear la Función de la nube, creó una cuenta de servicio con el correo electrónico en el formato [PROJECT_ID] @ appspot.gserviceaccount.com. Copia este correo electrónico para el siguiente paso.
Pase el cursor sobre el ícono Más para este nuevo conjunto de datos.
Haga clic en "Compartir conjunto de datos".
En la ventana emergente, ingrese el correo electrónico de la cuenta de servicio. Dale permiso "Can Edit".
Ejecutar el trabajo:
Puede probar el flujo de trabajo anterior ejecutando el proyecto ahora, en lugar de esperar la hora programada de UNIX. Para hacer esto:
- Abre la página de Cloud Scheduler en la consola.
- Haz clic en el botón "Ejecutar ahora".
- Abre BigQuery en la consola.
- Debajo de su conjunto de datos de salida, busque su [output_table_name], esto contendrá los datos.
Para obtener más información, lea nuestra documentación sobre la configuración de Cloud Scheduler con PubSub trigger y pruébelo utilizando uno de nuestros conjuntos de datos públicos de BigQuery.
No hay comentarios:
Publicar un comentario
Nota: solo los miembros de este blog pueden publicar comentarios.